Query-Time Augmentation
Overview
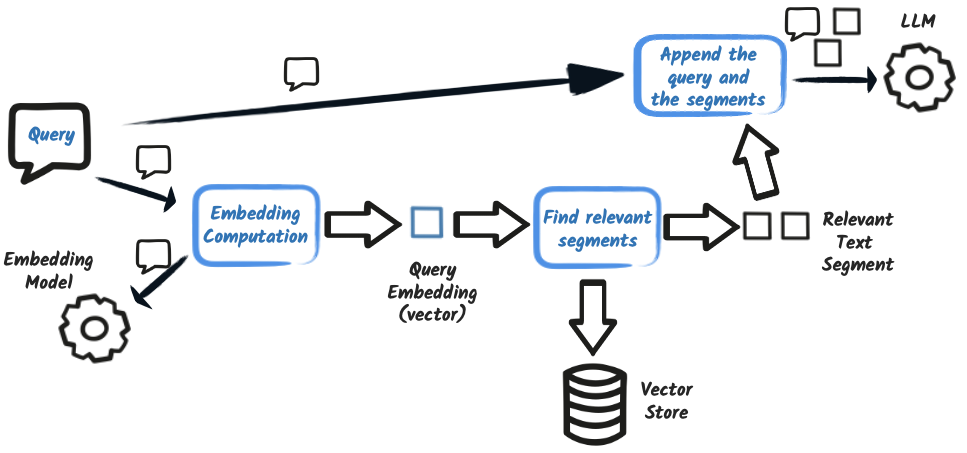
In a Retrieval-Augmented Generation (RAG) system, query-time augmentation refers to enriching the user’s input with relevant contextual information retrieved from trusted external sources. This process enhances factual accuracy and improves the quality of the LLM’s response.
This document describes how to build query-time augmentation pipelines using Quarkus LangChain4j, from naive RAG to more advanced contextual strategies.
Key Concepts
| Concept | Description |
|---|---|
Retriever |
A component that fetches relevant content based on the user query (typically via vector search) |
Content |
A piece of retrieved data (text segment, metadata) |
Augmentor |
A component that injects retrieved content into the prompt sent to the LLM |
Query Transformer |
An optional processor that rewrites or compresses the query |
Prompt Injector |
A logic that merges content and the user prompt |
Router |
(Advanced) Determines which retriever(s) to use for a query |
Aggregator |
(Advanced) Ranks, filters, or deduplicates results from multiple sources |
Dependencies on Ingestion
Query-time augmentation requires that documents were previously:
-
Split into meaningful chunks
-
Embedded using the same embedding model used at query time
-
Stored in a compatible vector store (embedding store)
-
Optionally enriched with metadata that can be used for ranking, filtering, or context expansion
Consistency is key: If your embedding model or chunking strategy changes, you must re-ingest documents. Otherwise, retrieval accuracy will suffer.
|
Dependency between the injection and the augmentation pipelines
There are strong dependencies between the ingestion pipeline and the query-time augmentation pipeline:
|
Naive Retrieval-Augmented Generation
Naive (also known as Frozen or Static RAG) RAG consists of a single retriever and a basic injector. The retriever fetches N relevant content pieces and the injector appends them to the user message.
INFO: Naive RAG is a simple yet effective strategy for query-time augmentation. It does not use dynamic query transformation, routing, or reranking. It simply retrieves relevant content and injects it into the prompt.
Example: Basic RetrievalAugmentor
@ApplicationScoped
public class RetrievalAugmentorExample implements Supplier<RetrievalAugmentor> {
private final RetrievalAugmentor augmentor;
RetrievalAugmentorExample(EmbeddingStore store, EmbeddingModel model) {
// Configure the content retriever, responsible for fetching relevant content based on the user query
var contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(model)
.embeddingStore(store)
.maxResults(3)
.build();
// Create the RetrievalAugmentor that combines the retriever and a default content injector
augmentor = DefaultRetrievalAugmentor
.builder()
.contentRetriever(contentRetriever)
.build();
}
@Override
public RetrievalAugmentor get() {
return augmentor;
}
}Example: Custom Content Injector
@Produces
@ApplicationScoped
// If you have multiple stores and embedding models, you can inject specific types:
public RetrievalAugmentor create(
PgVectorEmbeddingStore store,
BgeSmallEnQuantizedEmbeddingModel model) {
EmbeddingStoreContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(model)
.embeddingStore(store)
.maxResults(3)
.build();
return DefaultRetrievalAugmentor.builder()
.contentRetriever(retriever)
.contentInjector((contentList, userMessage) -> {
StringBuffer prompt = new StringBuffer(userMessage.singleText());
prompt.append("\nPlease, only use the following information:\n");
contentList.forEach(content -> prompt.append("- ").append(content.textSegment().text()).append("\n"));
return new UserMessage(prompt.toString());
})
.build();
}Contextual RAG
Contextual RAG involves:
-
Query transformation (e.g., compression)
-
Multiple retrievers (e.g., vector DB and web search)
-
Routing (decide which retriever(s) to use)
-
Reranking (scoring and filtering content)
-
Rich injection strategies
This setup is modular and fully supported by Quarkus LangChain4j. Each step is optional but recommended for production use cases.

Component Glossary
| Component | Purpose |
|---|---|
Query Transformer |
Modifies the query (e.g., compression or rewriting) |
Query Router |
Chooses which retriever(s) to use |
Aggregator |
Scores and combines results from multiple retrievers |
Injector |
Builds the final prompt by combining context and user input |
| The full implementation of contextual RAG (with routing, scoring, compression, etc.) is covered in Contextual RAG. |
Integration with AI Services
Quarkus LangChain4j automatically wires a RetrievalAugmentor into any AI service if a corresponding bean is available in the CDI context.
This makes it easy to enable RAG for any AI service:
@RegisterAiService
public interface Assistant {
// Automatically augmented if a RetrievalAugmentor is available
String chat(String userMessage);
}You can also explicitly reference a specific RetrievalAugmentor in the AI service annotation.
This is useful when multiple augmentors exist and you want full control over which one is used.
@RegisterAiService(retrievalAugmentor = RagRetrievalAugmentor.class)
public interface Assistant {
String chat(String userMessage);
}The retriever implementation must be exposed as a Supplier<RetrievalAugmentor> application scoped bean. This allows lazy initialization and flexible configuration.
The bean can be configured using @ConfigProperty, for instance:
@ApplicationScoped
public class RagRetrievalAugmentor implements Supplier<RetrievalAugmentor> {
@ConfigProperty(name = "rag.retrieval.max-results", defaultValue = "5")
int maxResults;
@Inject EmbeddingModel embeddingModel;
@Inject EmbeddingStore embeddingStore;
@Override
public RetrievalAugmentor get() {
EmbeddingStoreContentRetriever retriever =
EmbeddingStoreContentRetriever.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.maxResults(maxResults)
.build();
return DefaultRetrievalAugmentor.builder()
.contentRetriever(retriever)
.build();
}
}
To verify that your RetrievalAugmentor is used, you can inspect model logs (and check for the prompt augmentation) or inject it manually in a test class to verify its behavior.
|
Summary
Query-time augmentation is a critical phase of any RAG system. In Quarkus LangChain4j:
-
You build a RetrievalAugmentor that enriches queries with relevant content.
-
You choose between easyRAG, simple (naive) or advanced (contextual) strategies.
-
Your ingestion pipeline must match your augmentation setup in embedding model and data format.