Contextual Retrieval-Augmented Generation (RAG)
Overview
Contextual RAG enhances the standard Retrieval-Augmented Generation (RAG) pipeline by introducing dynamic and modular components such as:
-
Query compression
-
Multi-retriever support
-
Query routing
-
Content scoring and re-ranking
-
Custom injection logic
This approach enhances precision, scalability, and alignment with user intent in AI-assisted workflows. Quarkus LangChain4j fully supports contextual RAG through modular component APIs and CDI-based configuration, making it easy to tailor retrieval behavior to your application’s needs.
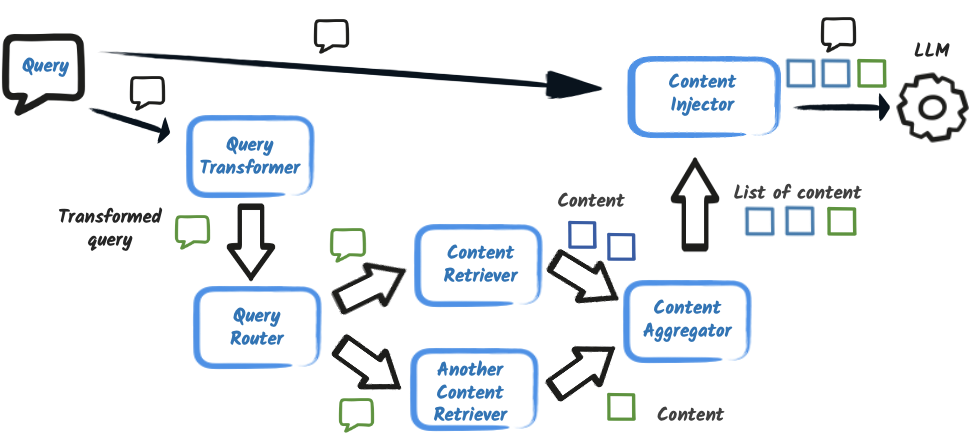
The diagram above illustrates the high-level flow of contextual RAG. It shows how user queries can be transformed, routed to one or more retrievers, filtered, and then injected into the LLM prompt for a response.
Component Overview
| Component | Description |
|---|---|
Query Transformer |
Rewrites or compresses the input query before retrieval |
Query Router |
Dynamically selects which retriever(s) to invoke |
Retriever |
Fetches contextually relevant content (e.g., vector DB, web search) |
Aggregator |
Scores, ranks, filters, or deduplicates content |
Injector |
Injects the retrieved content into the user’s prompt |
Implementing Contextual RAG in Quarkus
Each contextual RAG component can be implemented individually and combined using DefaultRetrievalAugmentor.builder().
1. Query Transformer and Query Compression
A QueryTransformer modifies or rewrites the input query before retrieval. This is particularly useful when user queries are verbose, contain filler words, or require normalization to match indexed document formats.
One common use case is query compression, where a ChatModel is used to rephrase the query concisely, preserving its intent while improving retrieval accuracy.
You can access the default query transformer as follows:
public QueryTransformer getDefaultQueryTransformer(ChatModel chatModel) {
return new CompressingQueryTransformer(chatModel);
}You can also create a custom implementation if you want more control:
public QueryTransformer createQueryTransformer(ChatModel chatModel) {
return question -> {
String compressed = chatModel.chat("Summarize this: " + question.text());
return List.of(Query.from(compressed));
};
}Using a transformer ensures your retrievers work with more focused queries, improving both latency and relevance.
2. Multiple Retrievers
In general, the RAG uses a vector store to retrieve relevant content based on the query embedding. But it’s not the only source of information. You can combine multiple sources, such as:
-
vector store (e.g., PGVector, Chroma, Weaviate)
-
web search (e.g., Tavily, Bing, Google)
-
knowledge bases (e.g., SQL, NoSQL databases)
-
full-text search engines (e.g., Elasticsearch, OpenSearch)
A content retriever is a component that fetches relevant content based on a query:
public interface ContentRetriever {
/**
* Retrieves relevant {@link Content}s using a given {@link Query}.
* The {@link Content}s are sorted by relevance, with the most relevant {@link Content}s appearing
* at the beginning of the returned {@code List<Content>}.
*
* @param query The {@link Query} to use for retrieval.
* @return A list of retrieved {@link Content}s.
*/
List<Content> retrieve(Query query);
}So you can provide many implementations of ContentRetriever to cover different data sources.
For some of them, Quarkus LangChain4j provides built-in implementations, such as:
public List<ContentRetriever> createContentRetrievers(EmbeddingModel model,
EmbeddingStore<TextSegment> store,
WebSearchEngine webSearchEngine) {
ContentRetriever vectorRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(model)
.embeddingStore(store)
.maxResults(3)
.build();
ContentRetriever webRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(webSearchEngine)
.build();
return List.of(vectorRetriever, webRetriever);
}| A Content Retriever implementation can use an LLM to transform the query before performing the actual retrieval, like transforming a query into an SQL query or a web search query. |
3. Query Router
The query router dynamically selects which retriever(s) to invoke based on the query content or context.
The default router will use all available retrievers, but you can create a custom one to route queries based on their content or type.
public QueryRouter createQueryRouter(ChatModel chatModel,
ContentRetriever vectorSearchRetriever,
ContentRetriever webSearchRetriever) {
// Create a query router that uses a chat model to route queries
return LanguageModelQueryRouter.builder()
.chatModel(chatModel)
.retrieverToDescription(Map.of(
vectorSearchRetriever, "Retrieve relevant documents about terms and conditions",
webSearchRetriever, "Retrieve relevant documents from the quarkus.io website"))
.build();
}Smarter routers can use a ChatModel to determine which retriever(s) to use based on the query content or context:
public QueryRouter createQueryRouter(ChatModel chatModel,
ContentRetriever vectorSearchRetriever,
ContentRetriever webSearchRetriever) {
// Create a query router that uses a chat model to route queries
return LanguageModelQueryRouter.builder()
.chatModel(chatModel)
.retrieverToDescription(Map.of(
vectorSearchRetriever, "Retrieve relevant documents about terms and conditions",
webSearchRetriever, "Retrieve relevant documents from the quarkus.io website"))
.build();
}You can also add a fallback if no retriever is selected:
public QueryRouter createQueryRouterWithFallback(ChatModel chatModel,
ContentRetriever vectorSearchRetriever,
ContentRetriever webSearchRetriever) {
// Create a query router that uses a chat model to route queries
return LanguageModelQueryRouter.builder()
.chatModel(chatModel)
.fallbackStrategy(LanguageModelQueryRouter.FallbackStrategy.ROUTE_TO_ALL)
.retrieverToDescription(Map.of(
vectorSearchRetriever, "Retrieve relevant documents about terms and conditions",
webSearchRetriever, "Retrieve relevant documents from the quarkus.io website"))
.build();
}4. Content Aggregation and Reranking
When multiple retrievers are used, you may want to score and filter the results to ensure only the most relevant content is included in the final prompt.
You can implement a custom ContentAggregator to score, (re-)rank, and filter the retrieved content.
public ContentAggregator createAggregator(ScoringModel model) {
return ReRankingContentAggregator.builder()
.scoringModel(model)
.minScore(0.6)
.build();
}Reranking needs a scoring model, which can be implemented using a ChatModel or an EmbeddingModel that computes similarity scores between the query and content, or be a custom scoring function.
You can also combine all result without reranking (the order may not be deterministic):
ContentAggregator aggregator = new DefaultContentAggregator();Reranking is covered in more detail in Reranking using scoring models.
5. Custom Content Injection
Control how the retrieved content is added to the final prompt:
public ContentInjector createContentInjector() {
return (contents, userMessage) -> {
StringBuilder prompt = new StringBuilder(userMessage.toString() + "\n\nRelevant facts:\n");
for (Content content : contents) {
prompt.append("- ").append(content.textSegment().text()).append("\n");
}
return UserMessage.userMessage(prompt.toString());
};
}You can use a ContentInjector to customize how the retrieved content is injected into the prompt.
| Implementing your own injector can be useful to later identify which part of the prompt has been augmented with RAG content and cleanup the memory to avoid out of date information. |
6. Final Assembly
@Produces
@ApplicationScoped
public RetrievalAugmentor createRetrievalAugmentor(
ChatModel chatModel, // Default chat model, you can also use @ModelName to select it
ScoringModel scoringModel) {
return DefaultRetrievalAugmentor.builder()
.queryTransformer(getDefaultQueryTransformer(chatModel))
.queryRouter(createQueryRouter(chatModel, getVectorSearchRetriever(), getWebSearchRetriever()))
.contentAggregator(createAggregator(scoringModel))
.contentInjector(createContentInjector())
.build();
}Best Practices
-
Keep transformer logic lightweight to avoid latency
-
Use metadata filters to constrain search domains (e.g., by language or topic)
-
Ensure retrievers use consistent chunking and embedding settings as ingestion
-
Tune scoring thresholds (e.g., minScore) for balance between recall and relevance
-
Implement timeouts or fallbacks for web-based retrievers
-
Write unit tests for injectors to confirm the prompt shape and guard against prompt injection