Ingestion Pipeline
Overview
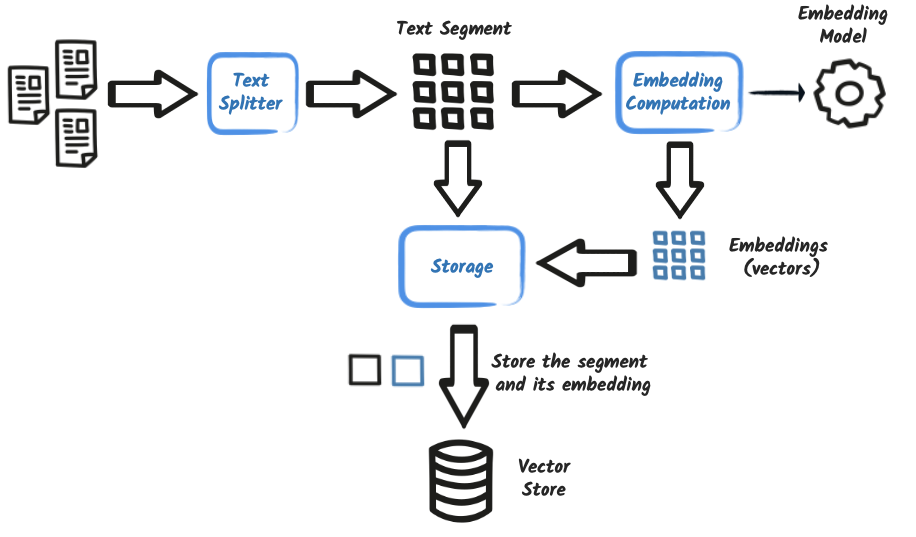
In a Retrieval-Augmented Generation (RAG) system, the ingestion pipeline is responsible for preparing external content so it can be efficiently retrieved and used at query time. The process involves reading documents, splitting them into segments, computing embeddings (vector representations), and storing them in a vector database.
| Looking for how to use this at query time? See Query-Time Augmentation. |
Key Concepts
| Concept | Description |
|---|---|
Document |
A unit of textual data to ingest (e.g., file, paragraph, article) |
Text Segment |
A smaller part of a document produced by a |
Document Splitter |
A strategy for breaking up large text blocks into smaller, meaningful chunks |
Metadata |
Additional information (e.g., file name, timestamp, author) |
Embedding Model |
A model that transforms text into numerical vectors (Embedding Models) |
Embedding Store |
A storage mechanism for vectors (e.g., PGVector, Chroma, Redis) |
Vector Store |
A synonym for an embedding store; optimized for similarity search |

Chunking Strategies
Chunking or document splitting is a critical step that affects both the quality and performance of retrieval.
Smaller chunks provide finer-grained retrieval and may reduce irrelevant content in the context window. However, if they’re too small, they can lose meaning. Larger chunks preserve context but may return less precise answers and consume more tokens. Using an overlap between chunks can improve continuity during retrieval.
| Sentence-based splitting is ideal for natural language documents (e.g. support tickets, articles), whereas fixed-size splitting works better for technical logs or structured formats. |
Fixed-Size Splitting
Split text into fixed-size blocks with optional overlaps:
import static dev.langchain4j.data.document.splitter.DocumentSplitters.recursive;
//
DocumentSplitter splitter = recursive(500, 50); // max segment size = 500 tokens, 50 token overlapThis strategy works well for semi-structured data (e.g., code, logs, long-form documents) and is easy to configure. The overlap helps preserve context across boundaries.
Sentence-Based Splitting with Context
You can split based on sentence boundaries, preserving semantic units:
DocumentBySentenceSplitter splitter = new DocumentBySentenceSplitter(200, 20); // 200 tokens, overlap of 20
List<TextSegment> segments = splitter.splitAll(docs);This strategy avoids splitting mid-sentence and typically yields more natural segments. You can also collect additional context around each segment for better semantic reasoning:
List<SegmentAndExtendedContext> withContext = collectTextSegmentAndExtendedContent(segments, 2, 2);
// ...
public record SegmentAndExtendedContext(TextSegment segment, String context) {}
private static List<SegmentAndExtendedContext> collectTextSegmentAndExtendedContent(List<TextSegment> input,
int before, int after) {
return IntStream.range(0, input.size())
.mapToObj(i -> {
TextSegment current = input.get(i);
StringBuilder builder = new StringBuilder();
// Collect the surrounding context
for (int j = Math.max(0, i - before); j <= Math.min(input.size() - 1, i + after); j++) {
builder.append(input.get(j).text()).append(" ");
}
String extendedContent = builder.toString().trim();
current.metadata().put("extended_content", extendedContent);
return new SegmentAndExtendedContext(current, extendedContent);
})
.toList();
}This enriches each segment with 2 segments before and 2 after, providing broader context for the embedding and retrieval stages:
-
For each segment at index i, it gathers before and after neighboring segments.
-
It concatenates their text with spaces.
-
It attaches this extended context to the
metadata()map of the segment under the key "extended_content". -
It returns a list of
SegmentAndExtendedContext, pairing each original segment with its extended context.
Metadata Enrichment
Metadata helps during query-time filtering or for ranking relevance:
Map<String, String> meta = new HashMap<>();
meta.put("file", "report.txt");
Document document = Document.document("Some content", new Metadata(meta));Text segments retain and propagate document-level metadata during splitting. You can enrich this metadata programmatically to support filtering (e.g., by source, date, language).
Embedding Models
An embedding model computes the vector representation of a segment. The model is typically injected using Quarkus LangChain4j:
@Inject
EmbeddingModel embeddingModel;Refer to Embedding Models for details on available options.
Vector Stores
Vector stores (aka embedding stores) store the segments and their vectors for later retrieval. Quarkus LangChain4j provides many options for vector stores, allowing you to choose the one that best fits your needs, such as:
-
PGVector
-
Redis
-
Infinispan
-
Chroma
You can see the full list of supported stores in the menu on the left.
When you have multiple stores, you can inject the one you need:
@Inject
PgVectorEmbeddingStore store;Basic Ingestion with Quarkus
Example 1: Simple ingestion with recursive splitter
The recursive(maxTokens, overlap) splitter uses token-based chunking. It recursively breaks down large text blocks into smaller pieces, ensuring that the resulting segments don’t exceed the specified size and overlap slightly to preserve context.
@ApplicationScoped
public class IngestorExampleWithPgvector {
@Inject PgVectorEmbeddingStore store;
@Inject EmbeddingModel embeddingModel;
public void ingest(List<Document> documents) {
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel)
.documentSplitter(recursive(500, 0))
.build();
ingestor.ingest(documents);
}
}|
Ingestion can be slow for large corpus.
You can parallelize embedding computation using a thread pool or batched embeddings ( |
Example 2: Startup ingestion from file system
@ApplicationScoped
public class RagIngestion {
public void ingest(@Observes StartupEvent ev, // Run on application startup
EmbeddingStore store, EmbeddingModel embeddingModel,
@ConfigProperty(name = "rag.location") Path documents) {
store.removeAll(); // Reset the vector store (for demo purposes only)
List<Document> list = FileSystemDocumentLoader.loadDocumentsRecursively(documents);
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel)
.documentSplitter(recursive(100, 25))
.build();
ingestor.ingest(list);
Log.info("Documents ingested successfully");
}
}Advanced Ingestion with Sentence Context
This approach enriches segments with nearby content, useful for summarization or semantic linking.
@ApplicationScoped
public class RagIngestion {
public static final String EXTENDED_CONTENT_KEY = "extended_content";
public static final String FILE_KEY = "file";
public void ingest(@Observes StartupEvent ev,
EmbeddingStore<TextSegment> store, EmbeddingModel embeddingModel,
@ConfigProperty(name = "rag.location") Path documents) throws IOException {
store.removeAll();
List<Document> docs = readDocuments(documents);
DocumentBySentenceSplitter splitter = new DocumentBySentenceSplitter(200, 20);
List<TextSegment> segments = splitter.splitAll(docs);
List<SegmentAndExtendedContext> segmentsWithContext = collectTextSegmentAndExtendedContent(segments, 2, 2);
List<TextSegment> embeddedSegments = segmentsWithContext.stream()
.map(SegmentAndExtendedContext::segment)
.toList();
List<Embedding> embeddings = embeddingModel.embedAll(embeddedSegments).content();
store.addAll(embeddings, embeddedSegments);
Log.info("Documents ingested successfully");
}
private static List<Document> readDocuments(Path documents) throws IOException {
return Files.list(documents)
.map(p -> Document.document(Files.readString(p), metadata(FILE_KEY, p.getFileName().toString())))
.toList();
}
public record SegmentAndExtendedContext(TextSegment segment, String context) {}
private static List<SegmentAndExtendedContext> collectTextSegmentAndExtendedContent(List<TextSegment> input,
int before, int after) {
return IntStream.range(0, input.size())
.mapToObj(i -> {
TextSegment textSegment = input.get(i);
String content = IntStream.rangeClosed(i - before, i + after)
.filter(j -> j >= 0 && j < input.size())
.mapToObj(j -> input.get(j).text())
.collect(Collectors.joining(" "));
textSegment.metadata().put(EXTENDED_CONTENT_KEY, content);
return new SegmentAndExtendedContext(textSegment, content);
})
.collect(Collectors.toList());
}
}Re-ingestion Strategies
You should re-ingest your documents when:
-
The content changes (e.g., new documents or updates)
-
You switch to a different embedding model
-
Your chunking strategy evolves
In this case, you should clean the vector store or track metadata to avoid duplicates.
Summary
The ingestion pipeline transforms documents into searchable vectors:
-
Documents are loaded and split into segments
-
Segments are enriched with metadata and optionally context
-
Embeddings are computed using a model
-
Segments and embeddings are stored into a vector store
This process ensures efficient and relevant retrieval at query time.
For unit testing, you can use an in-memory embedding store and mock the embedding model.