Messages and Memory in Quarkus LangChain4j
Chat models such as GPT-4 or Claude are fundamentally stateless: they do not retain any memory from previous requests.
All contextual understanding must come from the current input, which is why memory management and message representation are essential in multi-turn conversational systems.
This page explains how Quarkus LangChain4j handles messages, how it builds and manages memory, and how you can configure, extend, and control these behaviors.
Statelessness and Context Rehydration
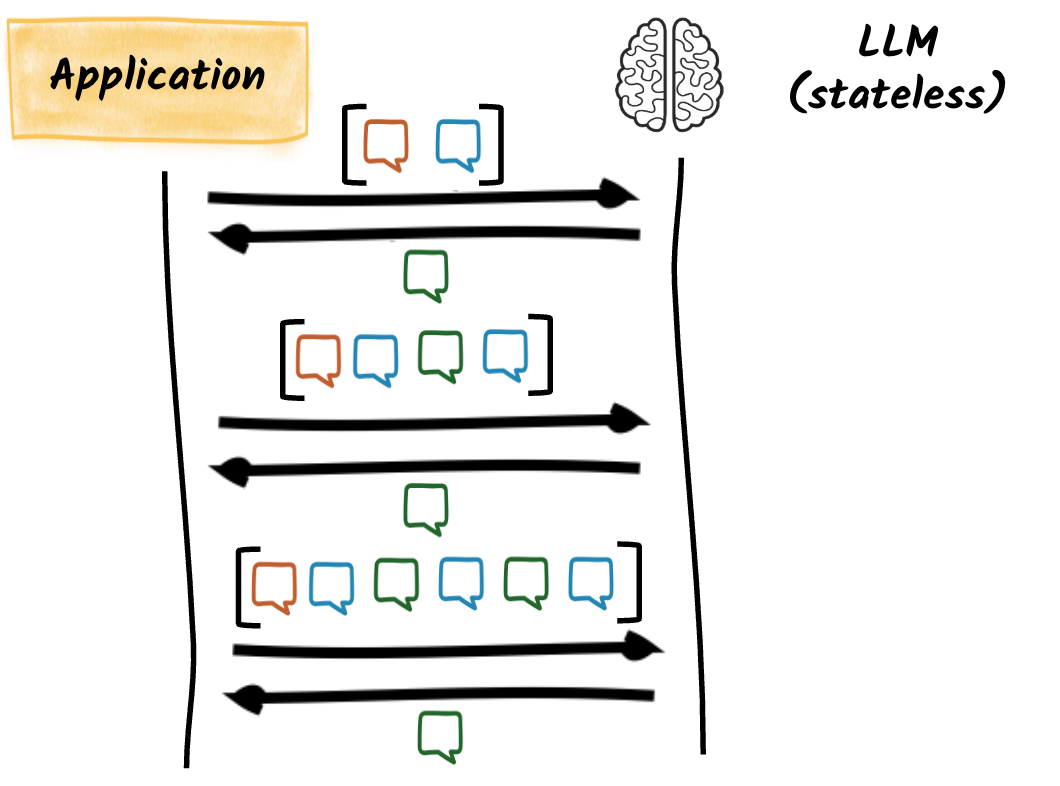
Large language models do not retain memory between calls. Each prompt is a standalone request.
To simulate continuity in a conversation, AI-Infused applications must resend the relevant message history: this is known as rehydrating context. Quarkus LangChain4j does this automatically when memory is configured.
This approach is flexible but costly: the entire memory (conversation history) is sent on every model invocation. Replaying a large memory consumes CPU and bandwidth.
Messages: The Building Blocks of Conversation
A message is a structured unit of interaction in a conversation. Each message has a role and content.
Supported roles include:
-
system message: Sets the overall behavior, tone, or instructions for the LLM. -
user message: Represents input from the user. Most interactions originate from user messages. -
assistant message: The response generated by the LLM. -
function call message: A special message used by the LLM to request the invocation of a function. -
function result message: Carries the result of a function call back to the model.
These messages form a history that is replayed at each interaction. This is often referred as the chat history or conversation history or context window.
An exchange refers to a complete interaction between the application and the model, including all messages sent and received during a conversation. In other words, an exchange represents a conversation that may consist of multiple messages from the user and responses from the assistant.
Here’s a simple multi-turn exchange/conversation:
| Role | Content |
|---|---|
system |
You are a helpful assistant |
user |
What’s the capital of France? |
assistant |
Paris |
user |
What’s the population? |
When the application sends the last message, it includes the entire history of messages to provide context for the model.
Memory and Its Purpose
Memory refers to the accumulation of previous messages in an exchange. It enables the model to:
-
understand ongoing context
-
resolve pronouns or references (like
itorthat) -
follow instructions given earlier
Each time a method is invoked, the full memory (chat history) is re-assembled and sent to the model.
However, this can lead to performance issues if the memory grows too large, as it may exceed the model’s token limit (context window) or cause latency.
In general, the memory is limited to the most recent messages, and older messages (except the system message) are evicted or summarized to keep the context manageable. This summarization is also known as context compression.
Memory Configuration in AI Services
Quarkus Langchain4J automatically manages the memory for your AI service:
@RegisterAiService
public interface MyAssistant {
String chat(String message);
}It retains conversation state and injects it during prompt construction depending on the AIService CDI scope.
It uses a default memory implementation that accumulates messages in a ChatMemory instance (stored in the memory of the application), evicting old messages when the max size is reached (10 messages by default).
You can customize the default size by setting the quarkus.langchain4j.chat-memory.memory-window.max-messages property in application.properties:
quarkus.langchain4j.chat-memory.memory-window.max-messages=20These settings apply to each exchange.
See Configuring the Default Memory for more details.
CDI Scope and Memory Isolation
Memory is tied to the CDI scope of the AI service. For each exchange (a potential multi-turn conversation), memory is isolated based on the service’s scope:
-
@ApplicationScoped— all users share the same memory (dangerous, requires the usage of@MemoryIdto isolate). -
@RequestScoped— memory is isolated per request, usually not useful except in function calling scenarios. -
@SessionScoped— memory per user/session (recommended for web apps, but limited to websocket-next for the moment).
|
AI Services are |
|
Using |
Configuring the Default Memory
To configure the default memory behavior, you can set properties in application.properties:
# Default memory type
quarkus.langchain4j.chat-memory.type=MESSAGE_WINDOW|TOKEN_WINDOW
# Maximum messages in memory (for MESSAGE_WINDOW)
quarkus.langchain4j.chat-memory.memory-window.max-messages=10
# Maximum tokens in memory (for TOKEN_WINDOW)
quarkus.langchain4j.chat-memory.token-window.max-tokens=1000When using MESSAGE_WINDOW, the memory retains the most recent messages up to the specified limit.
When using TOKEN_WINDOW, it retains messages until the total token count exceeds the limit.
Note that using TOKEN_WINDOW requires a TokenCountEstimator bean to be available in the application.
These memories are then stored in a ChatMemoryStore, which is an abstraction for storing and retrieving chat messages.
By default, it uses an in-memory store, meaning messages are lost when the application stops or restarts.
Custom Memory Implementations
The application can use a custom memory implementation by providing a ChatMemoryProvider bean:
@Singleton
public class CustomChatMemoryProvider implements ChatMemoryProvider {
/**
* Provides an instance of {@link ChatMemory}.
* This method is called each time an AI Service method (having a parameter annotated with {@link MemoryId})
* is called with a previously unseen memory ID.
* Once the {@link ChatMemory} instance is returned, it's retained in memory and managed by {@link dev.langchain4j.service.AiServices}.
*
* @param memoryId The ID of the chat memory.
* @return A {@link ChatMemory} instance.
*/
@Override
public ChatMemory get(Object memoryId) {
// ...
}
}Every AI service will use this ChatMemoryProvider to retrieve the memory instance associated with a specific memory ID.
To customize memory storage, you can implement your own ChatMemory and ChatMemoryStore.
For advanced use cases where you need multiple memory behavior, you can specify a custom memory implementation in the @RegisterAiService annotation with the chatMemoryProviderSupplier attribute:
@RegisterAiService(chatMemoryProviderSupplier = MyCustomChatMemoryProviderSupplier.class)
public interface MyAssistant {
String chat(String message);
}Implement the custom ChatMemoryProviderSupplier:
public class MyMemoryProviderSupplier implements Supplier<ChatMemoryProvider> {
@Override
public ChatMemoryProvider get() {
return new ChatMemoryProvider() {
@Override
public ChatMemory get(Object memoryId) {
return new MessageWindowChatMemory.Builder().maxMessages(5).build();
}
};
}
}Memory Backends with ChatMemoryStore
The default memory implementation is in-memory, meaning it is lost when the application stops or restarts.
To persist memory across restarts or share it between instances, you can implement a custom ChatMemoryStore.
Here is a simple example using Redis as backend:
@ApplicationScoped
public class MyMemoryStore implements ChatMemoryStore {
private static final TypeReference<List<ChatMessage>> MESSAGE_LIST_TYPE = new TypeReference<>() {
};
private final ValueCommands<String, byte[]> valueCommands;
private final KeyCommands<String> keyCommands;
public RedisChatMemoryStore(RedisDataSource redisDataSource) {
this.valueCommands = redisDataSource.value(new TypeReference<>() {});
this.keyCommands = redisDataSource.key(String.class);
}
@Override
public void deleteMessages(Object memoryId) {
// Remove all messages associated with the memoryId
// This is called when the exchange ends or the memory is no longer needed, like when the scope is terminated.
keyCommands.del(memoryId.toString());
}
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// Retrieve messages associated with the memoryId
byte[] bytes = valueCommands.get(memoryId.toString());
if (bytes == null) {
return Collections.emptyList();
}
try {
return QuarkusJsonCodecFactory.ObjectMapperHolder.MAPPER.readValue(
bytes, MESSAGE_LIST_TYPE);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// Store messages associated with the memoryId
try {
valueCommands.set(memoryId.toString(),
QuarkusJsonCodecFactory.ObjectMapperHolder.MAPPER.writeValueAsBytes(messages));
} catch (JsonProcessingException e) {
throw new UncheckedIOException(e);
}
}
}This is useful for:
-
long-lived memory
-
distributed services (e.g., multiple Quarkus pods/replicas)
-
external control over retention or eviction
Chat Memory Flush Strategy
By default, Quarkus Langchain4j accumulates messages in memory and only persists them to the ChatMemoryStore after the invocation completes successfully.
This enables seamless @Retry support - on failure the uncommitted messages are discarded and the retry starts with a clean slate.
When using IMMEDIATE flush, each message is written to the ChatMemoryStore immediately when it is added.
The store always reflects the current state of the conversation, even if the invocation eventually fails.
You can enable immediate flushing by providing a ChatMemoryFlushStrategy supplier via the chatMemoryFlushStrategySupplier attribute on @RegisterAiService:
@RegisterAiService(
chatMemoryFlushStrategySupplier = ImmediateFlushStrategySupplier.class
)
public interface MyAssistant {
String chat(String message);
}The supplier returns a ChatMemoryFlushStrategy enum value:
public class ImmediateFlushStrategySupplier implements Supplier<ChatMemoryFlushStrategy> {
@Override
public ChatMemoryFlushStrategy get() {
return ChatMemoryFlushStrategy.IMMEDIATE;
}
}The ChatMemoryFlushStrategy enum has two values:
-
DEFERRED(default) - buffer messages in memory and only writes them to theChatMemoryStoreafter the LLM invocation succeeds. -
IMMEDIATE- writes messages to theChatMemoryStoreimmediately when they are added.
If no strategy is configured, the default DEFERRED behavior is used.
Memory Compression and Eviction
LLMs have a token limit — if the full memory exceeds that limit, the prompt will be rejected or truncated.
When implementing memory, consider the following strategies:
-
Compression: Summarize or condense older messages to fit within the token limit.
-
Eviction: Remove older messages when the memory size exceeds the limit.
Compression is implemented using a ChatModel that summarizes the conversation history, while eviction simply removes the oldest messages.
Your custom ChatMemory implementation can handle these strategies, or you can use the built-in MessageWindowChatMemory or TokenWindowChatMemory (eviction based on message count or token count, respectively).
@MemoryId: Multi-Session Memory
To assign different memory instances to different users or conversations, annotate a method parameter with @MemoryId:
String chat(@MemoryId String sessionId, String message);The application code is responsible for providing a unique memory ID for each user or session. This gives you control over memory routing and enables multi-session support within a single service instance.
|
When using |
When using websocket-next, the @MemoryId will be automatically set to the session ID, allowing each user to have their own memory instance.
See Websockets for more details.
Summary
| Concept | Description |
|---|---|
Models are stateless |
They do not remember anything — memory must be resent on each call |
Message |
Forms the conversation history, with defined roles |
Exchange |
Multi-turn conversation, replaying the message history |
Memory |
Accumulation of messages, replayed on each request |
Scope |
Defines memory visibility and isolation |
Memory store |
Allows external persistence and custom retention policies |
Token |
Influences memory size, model limits, and cost |
MemoryId |
Binds conversations to different memory instances |
Compression |
Avoids hitting token limits via summarization or eviction |